Revisiting the six approaches
In this series, we looked at six different approaches to dependency injection.
- In the first post, we looked at “dependency retention” (inlining the dependencies) and “dependency rejection”, or keeping I/O at the edges of your implementation.
- In the second post, we looked at injecting dependencies using standard function parameters.
- In the third post, we looked at dependency handling using classic OO-style dependency injection and the FP equivalent: the Reader monad.
- In the fourth post, we looked at avoiding dependencies altogether by using the interpreter pattern.
In this final post, we’ll implement some simple requirements using all six approaches, so that you can see the differences. I won’t explain what’s going on in detail. For that, you should read the earlier posts.
Let’s look at a concrete use-case that we can use as a basis to experiment with different implementations.
Say that we have some kind of web app with users, and each user has a “profile” with their name, email, preferences, etc. A use-case for updating their profile might be something like this:
- Receive a new profile (parsed from a JSON request, say)
- Read the user’s current profile from the database
- If the profile has changed, update the user’s profile in the database
- If the email has changed, send a verification email message to the user’s new email
We will also add a little bit of logging into the mix.
Let’s start with the domain types we’re going to use:
module Domain =
type UserId = UserId of int
type UserName = string
type EmailAddress = EmailAddress of string
type Profile = {
UserId : UserId
Name : UserName
EmailAddress : EmailAddress
}
type EmailMessage = {
To : EmailAddress
Body : string
}
and here’s the infrastructure services for logging, database and email:
module Infrastructure =
open Domain
type ILogger =
abstract Info : string -> unit
abstract Error : string -> unit
type InfrastructureError =
| DbError of string
| SmtpError of string
type DbConnection = DbConnection of unit // dummy definition
type IDbService =
abstract NewDbConnection :
unit -> DbConnection
abstract QueryProfile :
DbConnection -> UserId -> Async<Result<Profile,InfrastructureError>>
abstract UpdateProfile :
DbConnection -> Profile -> Async<Result<unit,InfrastructureError>>
type SmtpCredentials = SmtpCredentials of unit // dummy definition
type IEmailService =
abstract SendChangeNotification :
SmtpCredentials -> EmailMessage -> Async<Result<unit,InfrastructureError>>
A few things to note about the infrastructure:
- The DB and Email services take an extra parameter:
DbConnectionandSmtpCredentialsrespectively. We’ll have to pass that in somehow, but it would be nice to hide it as it’s not a core part of the functionality. - The DB and Email services return an
AsyncResultwhich indicates that that they are impure and also might fail with anInfrastructureError. That’s helpful, but also means that combining them with other effects (such as Reader) will be annoying. - The logger does not return an
AsyncResult, even though it is impure. Using a logger in the middle of the domain code should not have any effect on the business logic.
We will assume that there is a global logger and default implementations of these services available to us.
Our first implementation will use all the dependencies directly, with no attempt at abstraction or parameterization.
Notes:
- The infrastructure services return
AsyncResult, and so we use anasyncResultcomputation expression to make the code easier to write and understand. - The decisions (
if currentProfile <> newProfile) and impure code are mixed together.
let updateCustomerProfile (newProfile:Profile) =
let dbConnection = defaultDbService.NewDbConnection()
let smtpCredentials = defaultSmtpCredentials
asyncResult {
let! currentProfile =
defaultDbService.QueryProfile dbConnection newProfile.UserId
if currentProfile <> newProfile then
globalLogger.Info("Updating Profile")
do! defaultDbService.UpdateProfile dbConnection newProfile
if currentProfile.EmailAddress <> newProfile.EmailAddress then
let emailMessage = {
To = newProfile.EmailAddress
Body = "Please verify your email"
}
globalLogger.Info("Sending email")
do! defaultEmailService.SendChangeNotification smtpCredentials emailMessage
}
As we discussed in the first post, I think this approach is fine if it is for a small script or if it is used to quickly assemble a prototype or sketch. But this code is very hard to test properly, and if it gets more complicated, I would strongly recommend refactoring to separate the pure code from the impure code – the “dependency rejection” approach.
When I discussed “dependency rejection” in an earlier post, I used this diagram to show the end goal: separating pure, deterministic code from impure, non-deterministic code.
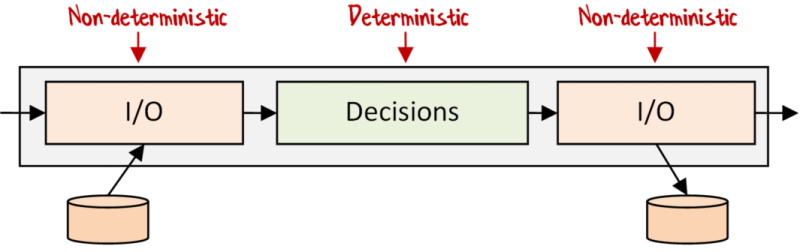
So let’s apply that approach to our example. The decision is:
- Do nothing
- Update the database only
- Update the database and also send a verification email
So let’s encode that decision as a type.
type Decision =
| NoAction
| UpdateProfileOnly of Profile
| UpdateProfileAndNotify of Profile * EmailMessage
And now the pure, decision-making part of the code can be implemented like this:
let updateCustomerProfile (newProfile:Profile) (currentProfile:Profile) =
if currentProfile <> newProfile then
globalLogger.Info("Updating Profile")
if currentProfile.EmailAddress <> newProfile.EmailAddress then
let emailMessage = {
To = newProfile.EmailAddress
Body = "Please verify your email"
}
globalLogger.Info("Sending email")
UpdateProfileAndNotify (newProfile, emailMessage)
else
UpdateProfileOnly newProfile
else
NoAction
In this implementation, we do not read from the database. Instead, we have the currentProfile passed in as a parameter.
And we do not write to the database. Instead, we return the Decision type to tell the later impure part what to do.
As a result, this code is very easy to test.
Note that the logger is not being passed as a parameter – we are just using the globalLogger. I think that, in some cases, logging can be an exception to the rule about accessing globals. If this bothers you, in the next section we’ll turn it into a parameter!
Now that the “pure” decision-making part of the code is done, we can implement the top-level code. It should be clear that we now have a impure/pure/impure sandwich, just as we wanted:
let updateCustomerProfile (newProfile:Profile) =
let dbConnection = defaultDbService.NewDbConnection()
let smtpCredentials = defaultSmtpCredentials
asyncResult {
// ----------- impure ----------------
let! currentProfile =
defaultDbService.QueryProfile dbConnection newProfile.UserId
// ----------- pure ----------------
let decision = Pure.updateCustomerProfile newProfile currentProfile
// ----------- impure ----------------
match decision with
| NoAction ->
()
| UpdateProfileOnly profile ->
do! defaultDbService.UpdateProfile dbConnection profile
| UpdateProfileAndNotify (profile,emailMessage) ->
do! defaultDbService.UpdateProfile dbConnection profile
do! defaultEmailService.SendChangeNotification smtpCredentials emailMessage
}
Breaking the code into two parts like this is very easy and has lots of benefits. So “dependency rejection” should always be the first refactoring that you do.
In the rest of this post, even as we use additional techniques, we will keep the decision-making part and the IO-using part separate.
We’ve now separated pure from impure code, except for the logger, which cannot be easily disentangled from the pure code.
Let’s address this logger problem. The easiest way to make testing easier, at least, is to pass the logger as a parameter to the pure core, like this:
let updateCustomerProfile (logger:ILogger) (newProfile:Profile) (currentProfile:Profile) =
if currentProfile <> newProfile then
logger.Info("Updating Profile")
if currentProfile.EmailAddress <> newProfile.EmailAddress then
...
logger.Info("Sending email")
UpdateProfileAndNotify (newProfile, emailMessage)
else
UpdateProfileOnly newProfile
else
NoAction
If we want to, we could also parameterize the services in the top-level impure code as well. If there are a lot of infrastructure services, it’s common to bundle them up into a single type:
type IServices = {
Logger : ILogger
DbService : IDbService
EmailService : IEmailService
}
A parameter of this type can then be passed into the top-level code, as shown below. Everywhere we were using the defaultDbService directly before, we are now using the services parameter. Note that the logger is extracted from the services and then passed as a parameter to the pure function that we implemented above.
let updateCustomerProfile (services:IServices) (newProfile:Profile) =
let dbConnection = services.DbService.NewDbConnection()
let smtpCredentials = defaultSmtpCredentials
let logger = services.Logger
asyncResult {
// ----------- Impure ----------------
let! currentProfile =
services.DbService.QueryProfile dbConnection newProfile.UserId
// ----------- pure ----------------
let decision = Pure.updateCustomerProfile logger newProfile currentProfile
// ----------- Impure ----------------
match decision with
| NoAction ->
()
| UpdateProfileOnly profile ->
do! services.DbService.UpdateProfile dbConnection profile
| UpdateProfileAndNotify (profile,emailMessage) ->
do! services.DbService.UpdateProfile dbConnection profile
do! services.EmailService.SendChangeNotification smtpCredentials emailMessage
}
Passing a services parameter like this makes it easy to mock the services or change the implementation. It’s a simple refactoring which doesn’t require any special expertise, so as with “dependency rejection”, this is one of the first refactorings I would do if the code is getting hard to test.
The OO way to pass dependencies is generally to pass them into the constructor when the object is created. This is not the default approach for a functional-first design, but if you are writing F# code that will be used from C#, or you are working within a C# framework that expects this kind of dependency injection, then this is the technique you should use.
// define a class with a constructor that accepts the dependencies
type MyWorkflow (services:IServices) =
member this.UpdateCustomerProfile (newProfile:Profile) =
let dbConnection = services.DbService.NewDbConnection()
let smtpCredentials = defaultSmtpCredentials
let logger = services.Logger
asyncResult {
// ----------- Impure ----------------
let! currentProfile = services.DbService.QueryProfile dbConnection newProfile.UserId
// ----------- pure ----------------
let decision = Pure.updateCustomerProfile logger newProfile currentProfile
// ----------- Impure ----------------
match decision with
| NoAction ->
()
| UpdateProfileOnly profile ->
do! services.DbService.UpdateProfile dbConnection profile
| UpdateProfileAndNotify (profile,emailMessage) ->
do! services.DbService.UpdateProfile dbConnection profile
do! services.EmailService.SendChangeNotification smtpCredentials emailMessage
}
As you can see, the UpdateCustomerProfile method has no explicit services parameter, instead using the services field thats in scope for the whole class.
The upside is that the method call itself is simpler. The downside is that the method now relies on the context of the class, making it harder to refactor and test in isolation.
The FP equivalent of delaying the injection of dependencies is the Reader type and its associated tools, such as the reader computation expression.
For more discussion on the Reader monad, see the earlier post.
Here’s the pure part of the code written to return a Reader containing the ILogger as its environment.
let updateCustomerProfile (newProfile:Profile) (currentProfile:Profile) =
reader {
let! (logger:ILogger) = Reader.ask
let decision =
if currentProfile <> newProfile then
logger.Info("Updating Profile")
if currentProfile.EmailAddress <> newProfile.EmailAddress then
let emailMessage = {
To = newProfile.EmailAddress
Body = "Please verify your email"
}
logger.Info("Sending email")
UpdateProfileAndNotify (newProfile, emailMessage)
else
UpdateProfileOnly newProfile
else
NoAction
return decision
}
The return type of updateCustomerProfile is Reader<ILogger,Decision>, just as we want.
We can run the Reader from our top level code like this:
let updateCustomerProfile (services:IServices) (newProfile:Profile) =
let logger = services.Logger
asyncResult {
// ----------- impure ----------------
let! currentProfile = ...
// ----------- pure ----------------
let decision =
Pure.updateCustomerProfile newProfile currentProfile
|> Reader.run logger
// ----------- impure ----------------
match decision with
... etc
If you really want to use Reader, I would recommend only using it to hide “effectless” dependencies in pure code, such as logging.
If you use Reader for impure code that returns different kinds of effects, such as AsyncResult, it can get quite messy.
To demonstrate this, let’s divide the impure code into two new functions, each of which returns a Reader:
The first function will read the profile from the database. It needs an IServices as the environment for the Reader, and it will return a AsyncResult<Profile,InfrastructureError>. So the overall return type will be Reader<IServices, AsyncResult<Profile,InfrastructureError>> which is pretty gnarly.
let getProfile (userId:UserId) =
reader {
let! (services:IServices) = Reader.ask
let dbConnection = services.DbService.NewDbConnection()
return services.DbService.QueryProfile dbConnection userId
}
The second function will handle the decision and update the profile in the database if needed. Again, it needs an IServices as the environment for the Reader, and it will return a unit wrapped in an AsyncResult. So the overall return type will be Reader<IServices, AsyncResult<unit,InfrastructureError>>.
let handleDecision (decision:Decision) =
reader {
let! (services:IServices) = Reader.ask
let dbConnection = services.DbService.NewDbConnection()
let smtpCredentials = defaultSmtpCredentials
let action = asyncResult {
match decision with
| NoAction ->
()
| UpdateProfileOnly profile ->
do! services.DbService.UpdateProfile dbConnection profile
| UpdateProfileAndNotify (profile,emailMessage) ->
do! services.DbService.UpdateProfile dbConnection profile
do! services.EmailService.SendChangeNotification smtpCredentials emailMessage
}
return action
}
Working with multiple different effects at the same time (Reader, Async, and Result in this case) is pretty painful. Languages like Haskell have some workarounds, but F# is not really designed to do this. The easiest way is to write a custom computation expression for the combined set of effects. The Async and Result effects are often used together, so it makes sense to have a special asyncResult computation expression. But if we add Reader into the mix, we would need something like a readerAsyncResult computation expression.
In my implementation below, I couldn’t be bothered to do that. Instead, I just run the Reader for each component function as needed, within the overall asyncResult expression. It’s ugly but it works.
let updateCustomerProfile (newProfile:Profile) =
reader {
let! (services:IServices) = Reader.ask
let getLogger services = services.Logger
return asyncResult {
// ----------- impure ----------------
let! currentProfile =
getProfile newProfile.UserId
|> Reader.run services
// ----------- pure ----------------
let decision =
Pure.updateCustomerProfile newProfile currentProfile
|> Reader.withEnv getLogger
|> Reader.run services
// ----------- impure ----------------
do! (handleDecision decision) |> Reader.run services
}
}
To finish up, we’ll look at applying the interpreter approach as discussed in the previous post.
To write the program, we will need to:
- Define the instruction sets we want to use. These will be data structures, not functions.
- Implement
IInstructionfor each of these instruction sets so it can be used with the generic “Program” library that we defined in the previous post. - Create some helper functions to make it easier to create instructions
- And then we can write the code using the
programcomputation expression
After that is done, we need to interpret the program:
- We will create sub-interpreters for each instruction set
- We will then create a top-level interpreter for the whole program that calls the sub-interpreters as needed.
We can choose to do this for just the pure part of the code, or for the impure part as well. Let’s start by just doing the pure part.
First we need to define the instruction set for the pure code. Right now, the only thing we need is logging. So we need:
- A
LoggerInstructiontype with a case for each logging action - An implementation of
IInstructionand its associatedMapmethod - Some helper functions to build the various instructions
Here’s the code:
type LoggerInstruction<'a> =
| LogInfo of string * next:(unit -> 'a)
| LogError of string * next:(unit -> 'a)
interface IInstruction<'a> with
member this.Map f =
match this with
| LogInfo (str,next) ->
LogInfo (str,next >> f)
| LogError (str,next) ->
LogError (str,next >> f)
:> IInstruction<_>
// helpers to use within the computation expression
let logInfo str = Instruction (LogInfo (str,Stop))
let logError str = Instruction (LogError (str,Stop))
With this instruction set, we can write the pure part, abstracting away the logger parameter that we needed in the earlier implementations.
let updateCustomerProfile (newProfile:Profile) (currentProfile:Profile) =
if currentProfile <> newProfile then program {
do! logInfo("Updating Profile")
if currentProfile.EmailAddress <> newProfile.EmailAddress then
let emailMessage = {
To = newProfile.EmailAddress
Body = "Please verify your email"
}
do! logInfo("Sending email")
return UpdateProfileAndNotify (newProfile, emailMessage)
else
return UpdateProfileOnly newProfile
}
else program {
return NoAction
}
The return type of updateCustomerProfile is just Program<Decision>. No mention of a specific ILogger anywhere!
Notice that there are sub programs for each branch of the main if/then/else expression. The rules for nesting let! and do! within computation expressions are not particularly intuitive, and you might get errors such as “This construct may only be used within computation expressions”. It sometimes takes a bit of tweaking to get it right.
If we want to replace all direct I/O calls with interpreted ones, then we will need to create instruction sets for them. So instead of the IDbService and IEmailService interfaces, we will have instruction types that look like this:
type DbInstruction<'a> =
| QueryProfile of UserId * next:(Profile -> 'a)
| UpdateProfile of Profile * next:(unit -> 'a)
interface IInstruction<'a> with
member this.Map f =
match this with
| QueryProfile (userId,next) ->
QueryProfile (userId,next >> f)
| UpdateProfile (profile,next) ->
UpdateProfile (profile, next >> f)
:> IInstruction<_>
type EmailInstruction<'a> =
| SendChangeNotification of EmailMessage * next:(unit-> 'a)
interface IInstruction<'a> with
member this.Map f =
match this with
| SendChangeNotification (message,next) ->
SendChangeNotification (message,next >> f)
:> IInstruction<_>
And the helpers to use within the computation expression:
let queryProfile userId =
Instruction (QueryProfile(userId,Stop))
let updateProfile profile =
Instruction (UpdateProfile(profile,Stop))
let sendChangeNotification message =
Instruction (SendChangeNotification(message,Stop))
As with the Reader implementation, we’ll break the system down into three components:
getProfile. An impure part that will read the profile from the database.updateCustomerProfile. The pure part that we implemented above.handleDecision. An impure part that will handle the decision and update the profile in the database if needed.
Here’s the implementation of getProfile using the queryProfile helper, which, as a reminder, actually creates the QueryProfile instruction but does not do anything.
let getProfile (userId:UserId) :Program<Profile> =
program {
return! queryProfile userId
}
Here’s the implementation of handleDecision. Note that for the NoAction case, I want to return unit, but wrapped in a Program. That’s exactly what program.Zero() is. I could also have used program { return() } to have the same effect.
let handleDecision (decision:Decision) :Program<unit> =
match decision with
| NoAction ->
program.Zero()
| UpdateProfileOnly profile ->
updateProfile profile
| UpdateProfileAndNotify (profile,emailMessage) ->
program {
do! updateProfile profile
do! sendChangeNotification emailMessage
}
With these three functions in hand, implementing the top-level function is straightforward.
let updateCustomerProfile (newProfile:Profile) =
program {
let! currentProfile = getProfile newProfile.UserId
let! decision = Pure.updateCustomerProfile newProfile currentProfile
do! handleDecision decision
}
It looks very clean – no AsyncResults anywhere! That makes it cleaner than the Reader version implemented earlier.
But now we come to the tricky part: implementing the sub-interpreters and the top-level interpreter.
This is made more complicated by the fact that the infrastructure services all return AsyncResult. Everything we do has to be lifted into that context.
Let’s go through the interpreter for DbInstruction first. (In the code below, I have added an “AS” suffix to show which values are AsyncResults.)
To understand what’s going on, let’s start with just one instruction, the interpreter for QueryProfile.
| QueryProfile (userId, next) ->
let profileAS = defaultDbService.QueryProfile dbConnection userId
let newProgramAS = (AsyncResult.map next) profileAS
interpret newProgramAS
First, we call the infrastructure service, which returns an AsyncResult.
let profileAS = defaultDbService.QueryProfile dbConnection userId
Then we call the next function to get the next Program to interpret. But the next function doesn’t work with AsyncResult, so we have to use AsyncResult.map to “lift” into a function that does. At that point we can call it with the profileAS and get back a new Program wrapped in an AsyncResult.
let newProgramAS = (AsyncResult.map next) profileAS
Finally, we can interpret the program. Normally, an interpreter would take a Program<'a> and return an 'a.
But with AsyncResult contaminating everything, the interpret function will need to take an AsyncResult<Program<'a>> and return an AsyncResult<'a>.
interpret newProgramAS // returns an AsyncResult<'a,InfrastructureError>
Here’s the full implementation of interpretDbInstruction:
let interpretDbInstruction (dbConnection:DbConnection) interpret inst =
match inst with
| QueryProfile (userId, next) ->
let profileAS = defaultDbService.QueryProfile dbConnection userId
let newProgramAS = (AsyncResult.map next) profileAS
interpret newProgramAS
| UpdateProfile (profile, next) ->
let unitAS = defaultDbService.UpdateProfile dbConnection profile
let newProgramAS = (AsyncResult.map next) unitAS
interpret newProgramAS
Note also that interpretDbInstruction takes a dbConnection as a parameter. The caller is going to have to pass that in.
The interpreter implementation for EmailInstruction is similar.
For the LoggerInstruction interpreter we need to tweak it somewhat, because the logger service does not use AsyncResult. In this case, we create a new program by calling next in the usual way, but then “lift” the result to an AsyncResult using asyncResult.Return.
let interpretLogger interpret inst =
match inst with
| LogInfo (str, next) ->
globalLogger.Info str
let newProgramAS = next() |> asyncResult.Return
interpret newProgramAS
| LogError (str, next) ->
...
Even though we have built the sub-interpreters for each instruction set, we cannot relax. The top-level interpreter is also quite complicated!
Here it is:
let interpret program =
// 1. get the extra parameters and partially apply them to make all the interpreters
// have a consistent shape
let smtpCredentials = defaultSmtpCredentials
let dbConnection = defaultDbService.NewDbConnection()
let interpretDbInstruction' = interpretDbInstruction dbConnection
let interpretEmailInstruction' = interpretEmailInstruction smtpCredentials
// 2. define a recursive loop function. It has signature:
// AsyncResult<Program<'a>,InfrastructureError>) -> AsyncResult<'a,InfrastructureError>
let rec loop programAS =
asyncResult {
let! program = programAS
return!
match program with
| Instruction inst ->
match inst with
| :? LoggerInstruction<Program<_>> as inst -> interpretLogger loop inst
| :? DbInstruction<Program<_>> as inst -> interpretDbInstruction' loop inst
| :? EmailInstruction<Program<_>> as inst -> interpretEmailInstruction' loop inst
| _ -> failwithf "unknown instruction type %O" (inst.GetType())
| Stop value ->
value |> asyncResult.Return
}
// 3. start the loop
let initialProgram = program |> asyncResult.Return
loop initialProgram
I’ve broken it down into three sections. Let’s go through them in turn.
First, we get the extra parameters (smtpCredentials and dbConnection) and create local variants of the interpreters with these parameters partially applied.
This puts all the interpreter functions into the same “shape”. It’s not strictly necessary, but it is a little bit cleaner I think.
Next, we define a local “loop” function, which is the actual interpreter loop. There are a number of advantages to using a local function like this.
- It can reuse values that are in scope, in this case using the same
dbConnectionall the way through the interpretation process. - It can have a different signature from the main
interpret. In this case, the loop accepts Programs wrapped in AsyncResults, rather than normal Programs.
Inside the the loop function, it handles the two cases of the Program:
- For the
Instructioncase, theloopfunction calls the sub-interpreters, passing in itself to recursively interpret the next step. - For the
Stopcase, it takes the normal value and wraps it into an AsyncResult usingasyncResult.Return
Finally, at the bottom, we start the loop. It needs an AsyncResult as input, so once again we have to lift the initial input program using asyncResult.Return
With the interpreter now available, the very top-most function can be completed. It works as follows:
- Call
Shell.updateCustomerProfile, which returns aProgram - Then interpret that program using
interpret, which returns anAsyncResult - Then run that
AsyncResultto get the final response (which in turn might need to be transformed into HTTP codes or similar)
let updateCustomerProfileApi (newProfile:Profile) =
Shell.updateCustomerProfile newProfile
|> interpret
|> Async.RunSynchronously
As we saw in the previous post, and as we see here, the interpreter approach results in very clean code where all the dependencies are hidden. All the nastiness of dealing with IO and stacked multiple effects (e.g. Async wrapping Result) is gone, or rather, pushed to the interpreter.
But getting to that clean code was a lot of extra work. For this program we needed only five instructions, yet we had to write around 100 extra lines of code to support them! And that was the simple version of the interpreter, dealing with only one kind of effect, AsyncResult. Furthermore, in practice, you might also need to avoid stack overflows by adding trampolines, which makes the code even more complicated. In general, I would say that is way too much effort for most situations.
So when would this be a good idea?
- If you have a use-case where you need to create a DSL or library for others to use and there are a small number of instructions, then the simplicity of the “front-end” use might outweigh the complexity of the “back-end” interpreter.
- If you need to do optimizations such as batching I/O requests, caching previous results, etc. By separating the program and the interpretation, you can do these optimizations behind the scenes while still having a clean front-end.
These requirements applied to Twitter, and Twitter’s engineering team developed a library called Stitch that does something like this. This video has a good explanation, or see this post. And Facebook engineering has a similar library called Haxl, developed for the same reasons.
In this post we applied the six different techniques to the same example. Which one did you like best?
Here’s my personal opinion of each approach:
- Dependency Retention is fine for small scripts or where you don’t need to test.
- Dependency Rejection is always a good idea and should always be used (with some exceptions for low-decision, high I/O workflows).
- Dependency Parameterization is generally a good idea for making pure code testable. Parameterizing the infrastructure services in the I/O heavy “edges” is not required but can often be useful.
- OO-style Dependency Injection should be used if you are interacting with OO-style C# or OO-style frameworks. Don’t make life hard for yourself!
- Reader monad is not a technique I would recommend unless you can see a clear benefit over the other techniques here.
- Dependency Interpretation is also not a technique I would recommend unless you have a specific use-case for it where none of the other techniques work.
Regardless of my opinion, all the techniques are useful to have in your toolbox. In particular, it’s good to understand how the Reader and Interpreter implementations work, even you don’t use much them in practice.
The source code for all the example code in this post is available at this gist.
The "Dependency Injection" series
-
Six approaches to dependency injection
-
Dependency injection using parameters
Six approaches to dependency injection, Part 2 -
Dependency injection using the Reader monad
Six approaches to dependency injection, Part 3 -
Dependency Interpretation
Six approaches to dependency injection, Part 4 -
Revisiting the six approaches
Six approaches to dependency injection, Part 5