Dependency injection using parameters
In this series, we are looking at six different approaches to dependency injection.
- In the first post, we looked at “dependency retention” (inlining the dependencies) and “dependency rejection” (keeping I/O at the edges of your implementation).
- In this post, we’ll look at “dependency parameterization” as a way of managing dependencies.
Given that you have made the effort to separate pure from impure code, you may still need to manage other dependencies. For example:
- How can we adapt the previous code to support a different comparison algorithm?
- How can we adapt the previous code to support mocking the I/O? (Assuming we want to mock the I/O rather than just doing integration testing).
To implement these kinds of “parameterization” requirements, a simple and obvious approach is just to pass the behavior that you want to parameterize into the main code as a function.
For example, if we want to support a different comparison algorithm, we can add the comparison options as a parameter like this:
let compareTwoStrings (comparison:StringComparison) str1 str2 =
// The StringComparison enum lets you pick culture and case-sensitivity options
let result = String.Compare(str1,str2,comparison)
if result > 0 then
Bigger
else if result < 0 then
Smaller
else
Equal
This function now has three parameters instead of the original two.
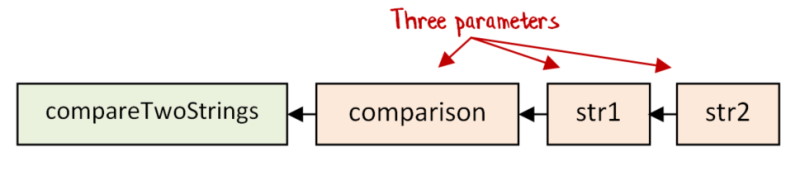
But by adding an extra parameter, we have broken the original contract for compareTwoStrings, which only had two inputs:
type CompareTwoStrings = string -> string -> ComparisonResult
No problem! We can just partially apply the comparison to get new functions that do conform to the contract.
// these both have the same type as `CompareTwoStrings`
let compareCaseSensitive = compareTwoStrings StringComparison.CurrentCulture
let compareCaseInsensitive = compareTwoStrings StringComparison.CurrentCultureIgnoreCase
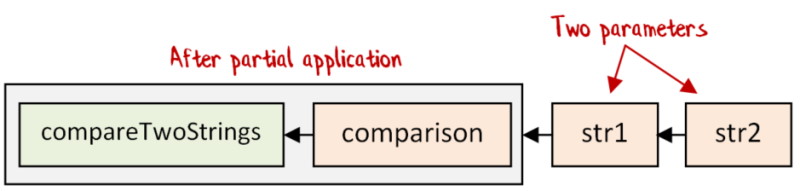
Note that the “strategy” parameter is deliberately positioned as the first parameter, to make partial application easy.
We can also use the same parameterization approach if we want to support multiple implementations of the I/O functions or other infrastructure services. We just pass them in as parameters.
// "infrastructure services" passed in as parameters
let compareTwoStrings (readLn:unit->string) (writeLn:string->unit) =
writeLn "Enter the first value"
let str1 = readLn()
writeLn "Enter the second value"
let str2 = readLn()
// etc
The top level code can then define the implementations of readLn and writeLn and then call the function above:
let program() =
let readLn() = Console.ReadLine()
let writeLn str = printfn "%s" str
// call the parameterized function
compareTwoStrings readLn writeLn
And of course, we could replace those console implementations with ones that used a file, or a socket, or whatever.
If functions depend on many infrastructure services, then rather than passing in each one as a separate parameter, it’s generally easier to combine them into a single object by using an interface or record of functions.
type IConsole =
abstract ReadLn : unit -> string
abstract WriteLn : string -> unit
The main function then accepts this interface as a single parameter:
// All "infrastructure services" passed in as a single interface
let compareTwoStrings (console:IConsole) =
console.WriteLn "Enter the first value"
let str1 = console.ReadLn()
console.WriteLn "Enter the second value"
let str2 = console.ReadLn()
// etc
and finally the very top level function (the “composition root”) builds the required interface and calls the main function with it:
let program() =
let console = {
new IConsole with
member this.ReadLn() = Console.ReadLine()
member this.WriteLn str = printfn "%s" str
}
// call the parameterized function
compareTwoStrings console
For “strategy” style dependencies, parameterization is the standard approach. It’s so common that it’s not even noteworthy. For example, it is seen in almost all the collection functions, such as List.map, List.sortBy, and so on.
For parameterizing infrastructure services and other non-deterministic dependencies, the benefits are less clear. Let’s look at some reasons why you might or might not want to do this.
Mockability. Yes, this approach does allow you to mock the infrastructure, but on the other hand, if you are keeping the I/O at the edges, you shouldn’t need to use mocks at all, as you will be unit testing only the pure segments of the pipeline.
To avoid vendor lock-in. Some people will argue that by parameterizing the infrastructure (database access, for example), it will make switching implementations later much easier. But again, if you are keeping the I/O separate, I think it’s perfectly OK to hard-code a specific database implementation at the edge. It is decoupled from the (pure) decision-making code, and should you ever need to swap to a different vendor, the process would be quite straightforward. Also, by not being too generic, you can exploit vendor-specific features of your service. (And if you don’t want to take advantage of vendor-specific features, then why are you even using that vendor?)
Encapsulation. If you have a long chain of components in a I/O heavy pipeline (with minimal business logic) and each component needs a different infrastructure service, it can often be much simpler just to pass the service directly into each component as a partially-applied parameter, and then wire the components together, like this:
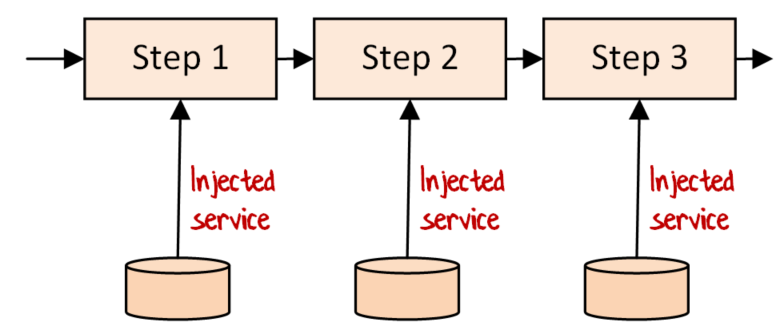
This keeps the components in the pipeline decoupled. Even though you are breaking some purity rules, F# is not Haskell, and I personally have no problem with using this approach if the pipeline is I/O heavy. If it is business logic heavy, then I would recommend that you stick with the dependency rejection approach.
If a non-deterministic dependency is used as parameter to a function, is that function impure? To my mind, no. You can pass an impure parameter to List.map as well – List.map doesn’t suddenly become impure.
In Haskell, any “impure” function is indicated by having IO in its type. The IO type will “contaminate” the call stack, and so the output of the main function will have IO as well and will be clearly signaled as impure. In F#, the compiler does not enforce this. Some people like to use Async as an equivalent to Haskell’s IO, as an indicator of non-determinism. I’m personally agnostic on this – it might be helpful in some situations but I wouldn’t enforce it as a general principle.
Sometimes, you need I/O or other non-determinism from deep within your pure domain code. In this case, dependency rejection won’t work and you will have to pass in a dependency somehow.
A common situation where this occurs is logging. Let’s say you need to log various actions in your core domain and you have a logger interface that looks like this:
type ILogger =
abstract Debug : string -> unit
abstract Info : string -> unit
abstract Error : string -> unit
How can you access an implementation of a logger from inside your domain?
The easiest option is just to access a global object (either a singleton logger or a “factory” that creates loggers). In general, globals are a bad idea, but for logging I think it is acceptable in exchange for having clean code.
If you do want to be explicit, then you will need to pass a logger as parameter to every function that needs it, like this:
let compareTwoStrings (logger:ILogger) str1 str2 =
logger.Debug "compareTwoStrings: Starting"
let result =
if str1 > str2 then
Bigger
else if str1 < str2 then
Smaller
else
Equal
logger.Info (sprintf "compareTwoStrings: result=%A" result)
logger.Debug "compareTwoStrings: Finished"
result
The advantage of doing this is that this function is completely standalone and easy to test in isolation. The downside is that if you have lots of deeply nested functions, this approach can get very tedious. In the next two posts we’ll look at other ways to handle this, using the reader monad and the interpreter pattern.
In this post, we looked at passing in dependencies using regular function parameters.
How does this compare to “dependency rejection” from the previous post? I would say that you should always start with the “dependency rejection” approach, moving I/O dependencies to the edge and away from the core as much as you can.
But in some cases, passing I/O dependencies is perfectly acceptable – in my opinion anyway! I/O heavy pipelines, or where you need logging, are situations where it may make sense to pass dependencies directly.
If you want to be really strict about purity, stay tuned! In the next post, we’ll look at the reader monad.
The source code for this post is available at this gist.
The "Dependency Injection" series
-
Six approaches to dependency injection
-
Dependency injection using parameters
Six approaches to dependency injection, Part 2 -
Dependency injection using the Reader monad
Six approaches to dependency injection, Part 3 -
Dependency Interpretation
Six approaches to dependency injection, Part 4 -
Revisiting the six approaches
Six approaches to dependency injection, Part 5