Dependency Interpretation
In this series, we are looking at six different approaches to dependency injection.
- In the first post, we looked at “dependency retention” (inlining the dependencies) and “dependency rejection” (keeping I/O at the edges of your implementation).
- In the second post, we looked at injecting dependencies using standard function parameters.
- In the third post, we looked at dependency handling using classic OO-style dependency injection and the FP equivalent: the Reader monad.
- In this post, we’ll look at avoiding dependencies altogether by using the interpreter pattern.
- In the next post, we’ll revisit all the techniques discussed and apply them to a new example.
The examples in this post build on the examples in previous posts, so please read them first.
In the “dependency rejection” approach we showed how to return a data structure (typically a “choice” type) that represented a decision. The last segment of the pipeline would then do various I/O actions based on the choice provided. This kept the core code pure and pushed all I/O to the edges.
We can take this approach further and extend it to cover all I/O. Instead of performing the I/O directly, we will return a data structure that will act as instructions to do various I/O actions later.
For our first attempt at this, let’s return a list of I/O instructions, like this:
type Instruction =
| ReadLn
| WriteLn of string
let readFromConsole() =
let cmd1 = WriteLn "Enter the first value"
let cmd2 = ReadLn
let cmd3 = WriteLn "Enter the second value"
let cmd4 = ReadLn
// return all the instructions I want the I/O part to do
[cmd1; cmd2; cmd3; cmd4]
And then interpret these instructions separately, like this:
let interpretInstruction instruction =
match instruction with
| ReadLn -> Console.ReadLine()
| WriteLn str -> printfn "%s" str
There are lots of problems with this approach, though. First, interpretInstruction doesn’t even compile! This is because each branch in the match instruction expression returns different types of data.
Even more seriously, there is no way to use the output of the interpreter in the middle of the code. For example, let’s say I wanted to use the result of the first ReadLn to change the output of the second WriteLn. In the design above, this is not possible at all.
What we want to do instead is an approach like the diagram below, where the output of each step of the interpreter is made available to the next line of our code.
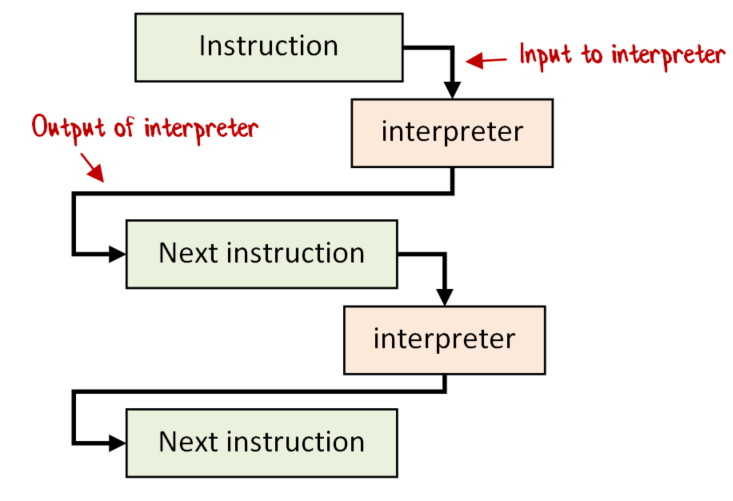
We can actually do this! The trick is that, when we create an instruction, we also provide a “next” function to be called after the interpretation has happened. After the interpreter executes an instruction, it then calls the “next” function with the result of the execution, which in turn calls back into the code under our control.
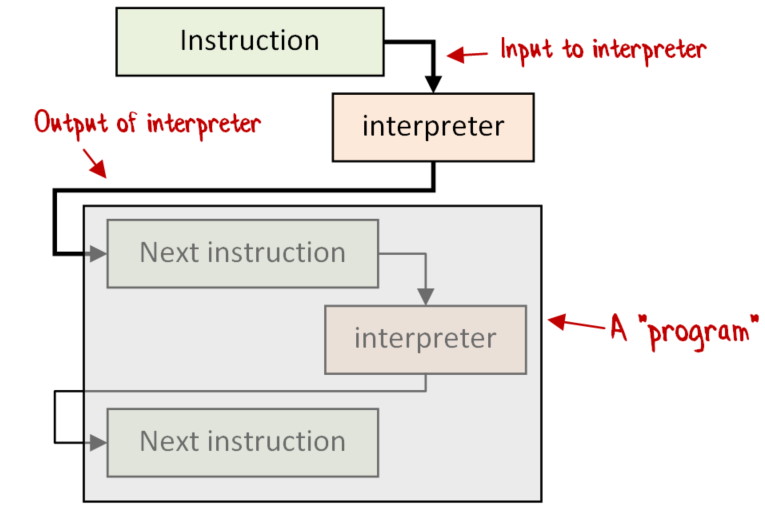
Let’s call the complete set of actions to interpret a “Program”. A Program consists of normal pure code intermixed with instructions to be interpreted.
Then for each instruction we will need to pass to the interpreter a pair: interpreterInput * (interpreterOutput -> Program).
For a concrete example, let’s look at ReadLn. A normal ReadLn function has the signature unit -> string. In our new approach, we will give the interpreter a unit and we want it to give us back a string. But that’s not quite right. Instead of feeding a string back to us, the interpreter will feed that string to the “next” function that we provide to the interpreter. The next function will therefore have the signature string -> Program, where Program is the rest of the code.
Similarly, the signature of the normal WriteLn is string -> unit, but in the interpreted approach, the pair we need to pass to the interpreter will be string * (unit -> Program). In other words, our input to the interpreter is a string, and then, after interpretation, the interpreter calls the next function with unit to get a new Program.
Let’s see some code that implements all this.
First, we define the set of instructions. Using the convention above, I’m going call the entire set of instructions a Program.
type Program<'a> =
| ReadLn of unit * next:(string -> Program<'a>)
| WriteLn of string * next:(unit -> Program<'a>)
| Stop of 'a
This particular program has three instructions:
ReadLn has no input to the interpreter. To process this instruction, the interpreter will read a line of text from somewhere, and then call the associated “next” function string->Program<'a> using the line that was read. That function will then return a new Program ready to be interpreted again.
WriteLn has a string input to the interpreter. To process this instruction, the interpreter will write that string to somewhere, and then call the associated “next” function unit->Program<'a>. That function will then return a new Program ready to be interpreted again.
If we just had these two instructions, we would have an endless loop, so we need one additional instruction to tell the interpreter to stop. I’ll call it Stop but you could also call it Done or Return or something similar. (Haskellers might call it Pure or Unit for reasons). Stop has an associated value but does not have a “next” function to call. When the interpreter sees this instruction it stops recursing and just returns the associated value. The value associated with Stop could be anything, and so that forces us to make the entire Program type generic (Program<'a>).
Here’s what some code using these instructions looks like:
let readFromConsole =
WriteLn ("Enter the first value" , fun () ->
ReadLn ( () , fun str1 ->
WriteLn ("Enter the second value", fun () ->
ReadLn ( () , fun str2 ->
Stop (str1,str2) // no "next" function
))))
You can see that after each instruction, there is a function which contains more instructions, and so on until we get to Stop, where we return the two strings as a tuple.
It’s very important to understand that readFromConsole is a data structure, not a function! It’s a WriteLn that contains a ReadLn that contains another WriteLn that contains another ReadLn that contains a Stop. The data structure contains functions, but nothing has actually been executed yet.
Now that we have built a data structure, we need an interpreter that will “execute” the data structure. The implementation should be easy to follow if you have understood the explanation so far. Notice that for ReadLn and WriteLn it is recursive, but at Stop it stops recursing and returns the supplied value.
let rec interpret program =
match program with
| ReadLn ((), next) ->
// 1. interpret the meaning of "ReadLn" to do actual I/O
let str = Console.ReadLine()
// 2. call "next" with the output of the interpretation.
// This gives us another Program
let nextProgram = next str
// 3. interpret the new Program (recursively)
interpret nextProgram
| WriteLn (str,next) ->
printfn "%s" str
let nextProgram = next()
interpret nextProgram
| Stop value ->
// return the overall result of the Program
value
We can now test that it works:
interpret readFromConsole
And it does! You can try it yourself using the code in the gist linked at the bottom of this post.
The readFromConsole implementation above is hard to write and ugly to look at. Can we make it easier to write and read this kind of code?
Yes, we can. The series of continuations at the end of each line (fun ... -> ...) is exactly the problem that computation expressions were designed to solve!
So let’s now build a computation expression for these instructions.
First we need to implement a bind function. It can be created mechanically using the following rules:
- for the
Stopcase, apply thefparameter to the return value. - for all other cases, replace the
nextfunction withnext >> bind f.
module Program =
let rec bind f program =
match program with
| ReadLn ((),next) -> ReadLn ((),next >> bind f)
| WriteLn (str,next) -> WriteLn (str, next >> bind f)
| Stop x -> f x
Note that bind must be defined with let rec so it can be used recursively.
Once we have bind, we can define the computation expression and its associated “builder” class.
- The
Bindmethod uses thebinddefined above. - The
ReturnandZeromethods useStopto return a value
type ProgramBuilder() =
member __.Return(x) = Stop x
member __.Bind(x,f) = Program.bind f x
member __.Zero() = Stop ()
// the builder instance
let program = ProgramBuilder()
It’s also convenient to define some helper functions to use within the computation expression. These helper function don’t “do” anything, they just create a data structure.
// helpers to use within the computation expression
let writeLn str = WriteLn (str,Stop)
let readLn() = ReadLn ((),Stop)
And now we can use the program computation expression and the two helper functions to re-implement the readFromConsole function in a cleaner way:
let readFromConsole = program {
do! writeLn "Enter the first value"
let! str1 = readLn()
do! writeLn "Enter the second value"
let! str2 = readLn()
return (str1,str2)
}
Amazingly, this code looks almost exactly like the code in the very first “dependency retention” example. No dependencies are passed in, and it’s all very clean. Of course, there’s a lot more complexity under the hood, and unlike the “dependency retention” example, we are not done yet. We also need to write the interpreter!
Now let’s extend this interpreter approach to build the example that we have been using in this series.
First we need to define the instructions in the program. Rather than putting all the instructions under one Program type, let’s see how we can build it from smaller pieces. This is exactly the kind of thing we will need to do when we have a more complex system.
We will define two separate instruction sets: one for the console instructions and one for the logger instructions, like this.
type ConsoleInstruction<'a> =
| ReadLn of unit * next:(string -> 'a)
| WriteLn of string * next:(unit -> 'a)
type LoggerInstruction<'a> =
| LogDebug of string * next:(unit -> 'a)
| LogInfo of string * next:(unit -> 'a)
Now we can define our Program type using the two instructions, plus Stop as before:
type Program<'a> =
| ConsoleInstruction of ConsoleInstruction<Program<'a>>
| LoggerInstruction of LoggerInstruction<Program<'a>>
| Stop of 'a
If we need to have more instructions, we simply add them as new choices.
Note: It would be nice if we could collapse all these choices into one higher-order choice that takes a type as a parameter. We’ll look at an F#-friendly way of doing this shortly.
Next we need to implement a bind function for the program. Now it turns out that we don’t need to implement bind for each of the instructions, we just need to implement a map function. The bind function is only needed for the program as a whole.
Here are the two map functions:
module ConsoleInstruction =
let rec map f program =
match program with
| ReadLn ((),next) -> ReadLn ((),next >> f)
| WriteLn (str,next) -> WriteLn (str, next >> f)
module LoggerInstruction =
let rec map f program =
match program with
| LogDebug (str,next) -> LogDebug (str,next >> f)
| LogInfo (str,next) -> LogInfo (str,next >> f)
And here is the bind function for the program:
module Program =
let rec bind f program =
match program with
| ConsoleInstruction inst ->
inst |> ConsoleInstruction.map (bind f) |> ConsoleInstruction
| LoggerInstruction inst ->
inst |> LoggerInstruction.map (bind f) |> LoggerInstruction
| Stop x ->
f x
The code for the computation expression is exactly the same as before:
type ProgramBuilder() =
member __.Return(x) = Stop x
member __.Bind(x,f) = Program.bind f x
member __.Zero() = Stop ()
// the builder instance
let program = ProgramBuilder()
Finally, we can implement the interpreter in the same way that we did earlier, except that this one has two sub-interpreters for the two instruction sets:
let rec interpret program =
let interpretConsole inst =
match inst with
| ReadLn ((), next) ->
let str = Console.ReadLine()
interpret (next str)
| WriteLn (str,next) ->
printfn "%s" str
interpret (next())
let interpretLogger inst =
match inst with
| LogDebug (str, next) ->
printfn "DEBUG %s" str
interpret (next())
| LogInfo (str, next) ->
printfn "INFO %s" str
interpret (next())
match program with
| ConsoleInstruction inst -> interpretConsole inst
| LoggerInstruction inst -> interpretLogger inst
| Stop value -> value
In the Reader approach from the previous post, we broke our mini-application into three components:
- readFromConsole
- compareTwoStrings
- writeToConsole
We will re-use this same partitioning for the interpreter approach as well.
First, let’s define some helpers that construct a Program for us.
let writeLn str = ConsoleInstruction (WriteLn (str,Stop))
let readLn() = ConsoleInstruction (ReadLn ((),Stop))
let logDebug str = LoggerInstruction (LogDebug (str,Stop))
let logInfo str = LoggerInstruction (LogInfo (str,Stop))
And now we can create the three components of the mini-application:
let readFromConsole = program {
do! writeLn "Enter the first value"
let! str1 = readLn()
do! writeLn "Enter the second value"
let! str2 = readLn()
return (str1,str2)
}
and
let compareTwoStrings str1 str2 = program {
do! logDebug "compareTwoStrings: Starting"
let result =
if str1 > str2 then
Bigger
else if str1 < str2 then
Smaller
else
Equal
do! logInfo (sprintf "compareTwoStrings: result=%A" result)
do! logDebug "compareTwoStrings: Finished"
return result
}
and
let writeToConsole (result:ComparisonResult) = program {
match result with
| Bigger ->
do! writeLn "The first value is bigger"
| Smaller ->
do! writeLn "The first value is smaller"
| Equal ->
do! writeLn "The values are equal"
}
Putting them all together, we have the final program:
let myProgram = program {
let! str1, str2 = readFromConsole
let! result = compareTwoStrings str1 str2
do! writeToConsole result
}
And to “execute” this program, we simply pass it into the interpreter:
interpret myProgram
The downside of the previous approach is that every time we need to add a new set of instructions, we need to modify the main Program type, which is brittle and anti-modular.
So let’s quickly look at an alternative approach.
In Haskell and other languages that support typeclasses (and in particular, Functors), we can construct a “Free Monad”. We’re writing F#, not Haskell, so let’s use interfaces instead!
First we define an interface that our instructions must implement. It has one member, the Map method:
type IInstruction<'a> =
abstract member Map : ('a->'b) -> IInstruction<'b>
Then we define our Program to use that type
type Program<'a> =
| Instruction of IInstruction<Program<'a>>
| Stop of 'a
Finally, we can define the bind using the map method associated with the instructions:
module Program =
let rec bind f program =
match program with
| Instruction inst ->
inst.Map (bind f) |> Instruction
| Stop x ->
f x
The computation expression builder is unchanged.
So far, this is completely generic and reusable code which has no knowledge of any particular instruction set.
To implement a specific workflow, we start by defining some instructions and their map method. Each of these instructions is unaware of, and hence decoupled from, the others.
type ConsoleInstruction<'a> =
| ReadLn of unit * next:(string -> 'a)
| WriteLn of string * next:(unit -> 'a)
interface IInstruction<'a> with
member this.Map f =
match this with
| ReadLn ((),next) -> ReadLn ((),next >> f)
| WriteLn (str,next) -> WriteLn (str, next >> f)
:> IInstruction<'b>
type LoggerInstruction<'a> =
| LogDebug of string * next:(unit -> 'a)
| LogInfo of string * next:(unit -> 'a)
interface IInstruction<'a> with
member this.Map f =
match this with
| LogDebug (str,next) -> LogDebug (str,next >> f)
| LogInfo (str,next) -> LogInfo (str,next >> f)
:> IInstruction<'b>
The only difference from the earlier implementation is that the Map method has to cast the result back to an IInstruction.
The helpers to use within the computation expression are almost the same, but now they use the more generic Instruction case.
let writeLn str = Instruction (WriteLn (str,Stop))
let readLn() = Instruction (ReadLn ((),Stop))
let logDebug str = Instruction (LogDebug (str,Stop))
let logInfo str = Instruction (LogInfo (str,Stop))
Although we are using the new generic Program type, the helper functions hide any changes, with the result that the main application code is unchanged. For example, readFromConsole looks exactly the same as before:
let readFromConsole = program {
do! writeLn "Enter the first value"
let! str1 = readLn()
do! writeLn "Enter the second value"
let! str2 = readLn()
return (str1,str2)
}
We want to build the interpreter in a modular way too. Again, to keep things decoupled, we want the interpreter for a particular instruction set to be unaware of the top level interpreter, so we will pass the interpret function in as a parameter:
// modular interpreter for ConsoleInstruction
let interpretConsole interpret inst =
match inst with
| ReadLn ((), next) ->
let str = Console.ReadLine()
interpret (next str)
| WriteLn (str,next) ->
printfn "%s" str
interpret (next())
// modular interpreter for LoggerInstruction
let interpretLogger interpret inst =
match inst with
| LogDebug (str, next) ->
printfn "DEBUG %s" str
interpret (next())
| LogInfo (str, next) ->
printfn "INFO %s" str
interpret (next())
To finish everything off, we just need to define the top-level interpreter. Again, this is very similar to the earlier implementation, except that we now match on the type of the instruction rather than exhaustively matching a fixed list of cases. It’s not as safe as having the compiler check everything for you, but if you forget to handle an instruction it will be very obvious very quickly!
let rec interpret program =
match program with
| Instruction inst ->
match inst with
| :? ConsoleInstruction<Program<_>> as i ->
interpretConsole interpret i
| :? LoggerInstruction<Program<_>> as i ->
interpretLogger interpret i
| _ -> failwithf "unknown instruction type %O" (inst.GetType())
| Stop value ->
value
The advantage of this approach is that it is much more modular. We can write subcomponents independently of each other, using different instruction sets, and then combine them later. The only thing that needs to change is the top-level interpreter for a particular workflow, which in turn can be built from a number of independent sub-interpreters.
For another example of using the Interpreter approach, see the last post in this series.
The interpreter approach that I’ve used here is closely related to the “Free Monad” approach used in Haskell and FP-style Scala. The Free Monad is even more abstract, and uses more math-y jargon to name the cases in the Program type, namely “Free” and “Pure” instead of “Instruction” and “Stop”. Nevertheless, I think it is worth spending some time understanding it, even if you rarely use it in practice.
Mark Seemann has written some very good posts on free monads in F#, such as one on a “recipe” that you can follow and another on how to “stack” free monads together.
For a real world story of using Interpreter/Free Monad in practice, here is a nice talk by Chris Myers, although he is using Scala. For a counter-example, see Free Monads Aren’t Free by Kelley Robinson.
As you can see, using the interpreter results in very clean code where all the dependencies are hidden. All the nastiness of dealing with IO (e.g. Async) is gone (or rather, pushed to the interpreter).
Another benefit is that you can easily switch out the interpreter if you need to work with different infrastructure. For example, I could change the logger interpretation to use a logger like Serilog, and I could change the console interpretation to use a file, or a socket. And “global” values (such as loggers) can easily managed in the interpreter loop without affecting the main program logic.
But as always, there are tradeoffs.
First, there is a lot of extra work. You have to define and interpret every possible I/O action that your workflow will need, which can be tedious. The number of operations can easily get out of hand if you are not careful. One advantage to building your system out of small independent workflows is that the number of operations shouldn’t be too high for any particular workflow.
Second, it’s a lot harder to understand what’s going on if you are not already familiar with this approach. Unlike the “dependency rejection” and “dependency parameterization” techniques, which do not require any special knowledge, both the Reader and the Interpreter approaches demand quite a lot of expertise. And if you ever need to step through code in a debugger, the deeply nested continuations will really make things very complicated.
Next, as always, one of the downsides of computation expressions is that it is hard to mix and match them. For example, in the previous post, I mentioned that it would be tricky to mix the Reader expressions with Result expressions and Async expressions. The interpreter approach alleviates this issue a little, as you never have to deal with things like Async in the main “program” code, and not even Result most of the time. But even so, when you do need to deal with this problem, it can be painful.
Finally, another issue is performance. If you have a large program with 1000’s of instructions, then you will have a very very deeply nested data structure. Interpretation might be slow, use a lot of memory, trigger more garbage collections, and might even cause stack overflows. There are workarounds (such as “trampolines”) but that makes the code even more complicated.
So, to sum up, I would only recommend this approach if (a) you really care about separating I/O from the pure code (b) everyone on the team is familiar with this technique (c) you have the skills and know-how to deal with any performance issues that might arise.
In the next post, we’ll revisit all the techniques discussed and apply them to a new example.
The source code for this post is available at this gist.
The "Dependency Injection" series
-
Six approaches to dependency injection
-
Dependency injection using parameters
Six approaches to dependency injection, Part 2 -
Dependency injection using the Reader monad
Six approaches to dependency injection, Part 3 -
Dependency Interpretation
Six approaches to dependency injection, Part 4 -
Revisiting the six approaches
Six approaches to dependency injection, Part 5