Algebraic type sizes and domain modelling
In this post, we’ll look at how to calculate the “size”, or cardinality, of an algebraic type, and see how this knowledge can help us with design decisions.
I’m going to define the “size” of a type by thinking of it as a set, and counting the number of possible elements.
For example, there are two possible booleans, so the size of the Boolean type is two.
Is there a type with size one? Yes – the unit type only has one value: ().
Is there a type with size zero? That is, is there a type that has no values at all? Not in F#, but in Haskell there is. It is called Void.
What about a type like this:
type ThreeState =
| Checked
| Unchecked
| Unknown
What is its size? There are three possible values, so the size is three.
What about a type like this:
type Direction =
| North
| East
| South
| West
Obviously, four.
I think you get the idea!
Let’s look at calculating the sizes of compound types now. If you remember from the understanding F# types series, there are two kinds of algebraic types: “product” types such as tuples and records, and “sum” types, called discriminated unions in F#.
For example, let’s say that we have a Speed as well as a Direction, and we combine them into a record type called Velocity:
type Speed =
| Slow
| Fast
type Velocity = {
direction: Direction
speed: Speed
}
What is the size of Velocity?
Here’s every possible value:
{direction=North; speed=Slow}; {direction=North; speed=Fast}
{direction=East; speed=Slow}; {direction=East; speed=Fast}
{direction=South; speed=Slow}; {direction=South; speed=Fast}
{direction=West; speed=Slow}; {direction=West; speed=Fast}
There are eight possible values, one for every possible combination of the two Speed values and the four Direction values.
We can generalize this into a rule:
- RULE: The size of a product type is the product of the sizes of the component types.
That is, given a record type like this:
type RecordType = {
a : TypeA
b : TypeB }
The size is calculated like this:
size(RecordType) = size(TypeA) * size(TypeB)
And similarly for a tuple:
type TupleType = TypeA * TypeB
The size is:
size(TupleType) = size(TypeA) * size(TypeB)
Sum types can be analyzed the same way. Given a type Movement defined like this:
type Movement =
| Moving of Direction
| NotMoving
We can write out and count all the possibilities:
Moving North
Moving East
Moving South
Moving West
NotMoving
So, five in all. Which just happens to be size(Direction) + 1. Here’s another fun one:
type ThingsYouCanSay =
| Yes
| Stop
| Goodbye
type ThingsICanSay =
| No
| GoGoGo
| Hello
type HelloGoodbye =
| YouSay of ThingsYouCanSay
| ISay of ThingsICanSay
Again, we can write out and count all the possibilities:
YouSay Yes
ISay No
YouSay Stop
ISay GoGoGo
YouSay Goodbye
ISay Hello
There are three possible values in the YouSay case, and three possible values in the ISay case, making six in all.
Again, we can make a general rule.
- RULE: The size of a sum or union type is the sum of the sizes of the component types.
That is, given a union type like this:
type SumType =
| CaseA of TypeA
| CaseB of TypeB
The size is calculated like this:
size(SumType) = size(TypeA) + size(TypeB)
What happens if we throw generic types into the mix?
For example, what is the size of a type like this:
type Optional<'a> =
| Something of 'a
| Nothing
Well, the first thing to say is that Optional<'a> is not a type but a type constructor. Optional<string> is a type. Optional<int> is a type, but Optional<'a> isn’t.
Nevertheless, we can still calculate its size by noting that size(Optional<string>) is just size(string) + 1, size(Optional<int>) is just size(int) + 1, and so on.
So we can say:
size(Optional<'a>) = size('a) + 1
Similarly, for a type with two generics like this:
type Either<'a,'b> =
| Left of 'a
| Right of 'b
we can say that its size can be calculated using the size of the generic components (using the “sum rule” above):
size(Either<'a,'b>) = size('a) + size('b)
What about a recursive type? Let’s look at the simplest one, a linked list.
A linked list is either empty, or it has a cell with a tuple: a head and a tail. The head is an 'a and the tail is another list. Here’s the definition:
type LinkedList<'a> =
| Empty
| Node of head:'a * tail:LinkedList<'a>
To calculate the size, let’s assign some names to the various components:
let S = size(LinkedList<'a>)
let N = size('a)
Now we can write:
S =
1 // Size of "Empty" case
+ // Union type
N * S // Size of "Cell" case using tuple size calculation
Let’s play with this formula a bit. We start with:
S = 1 + (N * S)
and let’s substitute the last S with the formula to get:
S = 1 + (N * (1 + (N * S)))
If we clean this up, we get:
S = 1 + N + (N^2 * S)
(where N^2 means “N squared”)
Let’s substitute the last S with the formula again:
S = 1 + N + (N^2 * (1 + (N * S)))
and clean up again:
S = 1 + N + N^2 + (N^3 * S)
You can see where this is going! The formula for S can be expanded out indefinitely to be:
S = 1 + N + N^2 + N^3 + N^4 + N^5 + ...
How can we interpret this? Well, we can say that a list is a union of the following cases:
- an empty list(size = 1)
- a one element list (size = N)
- a two element list (size = N x N)
- a three element list (size = N x N x N)
- and so on.
And this formula has captured that.
As an aside, you can calculate S directly using the formula S = 1/(1-N), which means that a list of Direction (size=4) has size “-1/3”.
Hmmm, that’s strange! It reminds me of this “-1/12” video.
What about functions? Can they be sized?
Yes, all we need to do is write down every possible implementation and count them. Easy!
For example, say that we have a function SuitColor that maps a card Suit to a Color, red or black.
type Suit = Heart | Spade | Diamond | Club
type Color = Red | Black
type SuitColor = Suit -> Color
One implementation would be to return red, no matter what suit was provided:
(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Red)
Another implementation would be to return red for all suits except Club:
(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Black)
In fact we can write down all 16 possible implementations of this function:
(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Red)
(Heart -> Red); (Spade -> Red); (Diamond -> Red); (Club -> Black)
(Heart -> Red); (Spade -> Red); (Diamond -> Black); (Club -> Red)
(Heart -> Red); (Spade -> Red); (Diamond -> Black); (Club -> Black)
(Heart -> Red); (Spade -> Black); (Diamond -> Red); (Club -> Red)
(Heart -> Red); (Spade -> Black); (Diamond -> Red); (Club -> Black) // the right one!
(Heart -> Red); (Spade -> Black); (Diamond -> Black); (Club -> Red)
(Heart -> Red); (Spade -> Black); (Diamond -> Black); (Club -> Black)
(Heart -> Black); (Spade -> Red); (Diamond -> Red); (Club -> Red)
(Heart -> Black); (Spade -> Red); (Diamond -> Red); (Club -> Black)
(Heart -> Black); (Spade -> Red); (Diamond -> Black); (Club -> Red)
(Heart -> Black); (Spade -> Red); (Diamond -> Black); (Club -> Black)
(Heart -> Black); (Spade -> Black); (Diamond -> Red); (Club -> Red)
(Heart -> Black); (Spade -> Black); (Diamond -> Red); (Club -> Black)
(Heart -> Black); (Spade -> Black); (Diamond -> Black); (Club -> Red)
(Heart -> Black); (Spade -> Black); (Diamond -> Black); (Club -> Black)
Another way to think of it is that we can define a record type where each value represents a particular implementation:
which color do we return for a Heart input, which color do we return for a Spade input, and so on.
The type definition for the implementations of SuitColor would therefore look like this:
type SuitColorImplementation = {
Heart : Color
Spade : Color
Diamond : Color
Club : Color }
What is the size of this record type?
size(SuitColorImplementation) = size(Color) * size(Color) * size(Color) * size(Color)
There are four size(Color) here. In other words, there is one size(Color) for every input, so we could write this as:
size(SuitColorImplementation) = size(Color) to the power of size(Suit)
In general, then, given a function type:
type Function<'input,'output> = 'input -> 'output
The size of the function is size(output type) to the power of size(input type):
size(Function) = size(output) ^ size(input)
Lets codify that into a rule too:
- RULE: The size of a function type is
size(output type)to the power ofsize(input type).
All right, that is all very interesting, but is it useful?
Yes, I think it is. I think that understanding sizes of types like this helps us design conversions from one type to another, which is something we do a lot of!
Let’s say that we have a union type and a record type, both representing a yes/no answer:
type YesNoUnion =
| Yes
| No
type YesNoRecord = {
isYes: bool }
How can we map between them?
They both have size=2, so we should be able to map each value in one type to the other, and vice versa:
let toUnion yesNoRecord =
if yesNoRecord.isYes then
Yes
else
No
let toRecord yesNoUnion =
match yesNoUnion with
| Yes -> {isYes = true}
| No -> {isYes = false}
This is what you might call a “lossless” conversion. If you round-trip the conversion, you can recover the original value. Mathematicians would call this an isomorphism (from the Greek “equal shape”).
What about another example? Here’s a type with three cases, yes, no, and maybe.
type YesNoMaybe =
| Yes
| No
| Maybe
Can we losslessly convert this to this type?
type YesNoOption = { maybeIsYes: bool option }
Well, what is the size of an option? One plus the size of the inner type, which in this case is a bool. So size(YesNoOption) is also three.
Here are the conversion functions:
let toYesNoMaybe yesNoOption =
match yesNoOption.maybeIsYes with
| None -> Maybe
| Some b -> if b then Yes else No
let toYesNoOption yesNoMaybe =
match yesNoMaybe with
| Yes -> {maybeIsYes = Some true}
| No -> {maybeIsYes = Some false}
| Maybe -> {maybeIsYes = None}
So we can make a rule:
- RULE: If two types have the same size, you can create a pair of lossless conversion functions
Let’s try it out. Here’s a Nibble type and a TwoNibbles type:
type Nibble = {
bit1: bool
bit2: bool
bit3: bool
bit4: bool }
type TwoNibbles = {
high: Nibble
low: Nibble }
Can we convert TwoNibbles to a byte and back?
The size of Nibble is 2 x 2 x 2 x 2 = 16 (using the product size rule), and the size of TwoNibbles is size(Nibble) x size(Nibble), or 16 x 16, which is 256.
So yes, we can convert from TwoNibbles to a byte and back.
What happens if the types are different sizes?
If the target type is “larger” than the source type, then you can always map without loss, but if the target type is “smaller” than the source type, you have a problem.
For example, the int type is smaller than the string type. You can convert an int to a string accurately, but you can’t convert a string to an int easily.
If you do want to map a string to an int, then some of the non-integer strings will have to be mapped to a special, non-integer value in the target type:
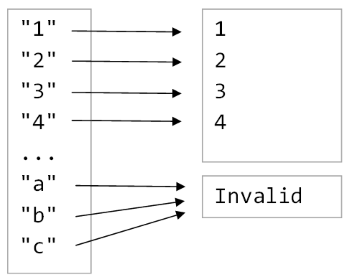
In other words we know from the sizes that the target type can’t just be an int type, it must be an int + 1 type. In other words, an Option type!
Interestingly, the Int32.TryParse function in the BCL returns two values, a success/failure bool and the parsed result as an int. In other words, a tuple bool * int.
The size of that tuple is 2 x int, many more values that are really needed. Option types ftw!
Now let’s say we are converting from a string to a Direction. Some strings are valid, but most of them are not. But this time, instead of having one invalid case, let’s also
say that we want to distinguish between empty inputs, inputs that are too long, and other invalid inputs.
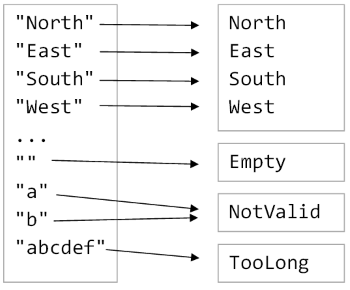
We can’t model the target with an Option any more, so let’s design a custom type that contains all seven cases:
type StringToDirection_V1 =
| North
| East
| South
| West
| Empty
| NotValid
| TooLong
But this design mixes up successful conversions and failed conversions. Why not separate them?
type Direction =
| North
| East
| South
| West
type ConversionFailure =
| Empty
| NotValid
| TooLong
type StringToDirection_V2 =
| Success of Direction
| Failure of ConversionFailure
What is the size of StringToDirection_V2?
There are 4 choices of Direction in the Success case, and three choices of ConversionFailure in the Failure case,
so the total size is seven, just as in the first version.
In other words, both of these designs are equivalent and we can use either one.
Personally, I prefer version 2, but if we had version 1 in our legacy code, the good news is that we can losslessly convert from version 1 to version 2 and back again. Which in turn means that we can safely refactor to version 2 if we need to.
Knowing that different types can be losslessly converted allows you to tweak your domain designs as needed.
For example, this type:
type Something_V1 =
| CaseA1 of TypeX * TypeY
| CaseA2 of TypeX * TypeZ
can be losslessly converted to this one:
type Inner =
| CaseA1 of TypeY
| CaseA2 of TypeZ
type Something_V2 =
TypeX * Inner
or this one:
type Something_V3 = {
x: TypeX
inner: Inner }
Here’s a real example:
- You have a website where some users are registered and some are not.
- For all users, you have a session id
- For registered users only, you have extra information
We could model that requirement like this:
module Customer_V1 =
type UserInfo = {name:string} //etc
type SessionId = SessionId of int
type WebsiteUser =
| RegisteredUser of SessionId * UserInfo
| GuestUser of SessionId
or alternatively, we can pull the common SessionId up to a higher level like this:
module Customer_V2 =
type UserInfo = {name:string} //etc
type SessionId = SessionId of int
type WebsiteUserInfo =
| RegisteredUser of UserInfo
| GuestUser
type WebsiteUser = {
sessionId : SessionId
info: WebsiteUserInfo }
Which is better? In one sense, they are both the “same”, but obviously the best design depends on the usage pattern.
- If you care more about the type of user than the session id, then version 1 is better.
- If you are constantly looking at the session id without caring about the type of user, then version 2 is better.
The nice thing about knowing that they are isomorphic is that you can define both types if you like, use them in different contexts, and losslessly map between them as needed.
We have all these nice domain types like Direction or WebsiteUser but at some point we need to interface with the outside world – store them in a database,
receive them as JSON, etc.
The problem is that the outside world does not have a nice type system! Everything tends to be primitives: strings, ints and bools.
Going from our domain to the outside world means going from types with a “small” set of values to types with a “large” set of values, which we can do straightforwardly. But coming in from the outside world into our domain means going from a “large” set of values to a “small” set of values, which requires validation and error cases.
For example, a domain type might look like this:
type DomainCustomer = {
Name: String50
Email: EmailAddress
Age: PositiveIntegerLessThan130 }
The values are constrained: max 50 chars for the name, a validated email, an age which is between 1 and 129.
On the other hand, the DTO type might look like this:
type CustomerDTO = {
Name: string
Email: string
Age: int }
The values are unconstrained: any string for the name, a unvalidated email, an age that can be any of 2^32 different values, including negative ones.
This means that we cannot create a CustomerDTO to DomainCustomer mapping. We have to have at least one other value (DomainCustomer + 1) to map the
invalid inputs onto, and preferably more to document the various errors.
This leads naturally to the Success/Failure model as described in my functional error handling talk,
The final version of the mapping would then be from a CustomerDTO to a SuccessFailure<DomainCustomer> or similar.
So that leads to the final rule:
- RULE: Trust no one. If you import data from an external source, be sure to handle invalid input.
If we take this rule seriously, it has some knock on effects, such as:
- Never try to deserialize directly to a domain type (e.g. no ORMs), only to DTO types.
- Always validate every record you read from a database or other “trusted” source.
You might think that having everything wrapped in a Success/Failure type can get annoying, and this is true (!), but there are ways to make this easier.
See this post for example.
The “algebra” of algebraic data types is well known. There is a good recent summary in “The algebra (and calculus!) of algebraic data types” and a series by Chris Taylor.
And after I wrote this, I was pointed to two similar posts:
- One by Tomas Petricek with almost the same content!
- One by Bartosz Milewski in his series on category theory.
As some of those posts mention, you can do strange things with these type formulas, such as differentiate them!
If you like academic papers, you can read the original discussion of derivatives in “The Derivative of a Regular Type is its Type of One-Hole Contexts”(PDF) by Conor McBride from 2001, and a follow up in “Differentiating Data Structures”(PDF) [Abbott, Altenkirch, Ghani, and McBride, 2005].
This might not be the most exciting topic in the world, but I’ve found this approach both interesting and useful, and I wanted to share it with you.
Let me know what you think. Thanks for reading!