Analysis of Roslyn vs. the F# compiler
After a long wait, the Roslyn project (C# compiler and analysis tools) has finally been released to much excitement (HN and Reddit and introductory post here).
Immediately, I got a request to do a follow up to my previous analysis of C# and F# code “in the wild” and apply a similar analysis to Roslyn, comparing it with the (already open source) F# compiler.
You might ask, is it really fair to compare such different projects? Are they doing the same amount of work? You could argue that perhaps there are many things that Roslyn does that the F# compiler does not (e.g. analysis). But equally there are many things that the F# compiler does that Roslyn does not (e.g. type inference).
Without delving into the sources deeply, I can’t say which project does “more work”, and so I won’t be comparing them on that basis, or saying that one is somehow “better” than the other.
Nevertheless, I do think that it is valid to see if the implementation language has an effect on size, modularity, and other metrics, especially because they are both projects addressing the same domain: compiling and analyzing code.
In other words, I’m not trying to compare features, I’m just interested to see if the choice of implementation language leaves traces that can be measured easily.
I am doing this out of genuine curiosity. I cannot confess to being unbiased (as the name of this site demonstrates!), but I will provide the detailed results and the code I used, so that you can see that my conclusions are based on real data.
So, here goes…
I am going to treat these projects as black boxes, so all data will be derived from analyzing the source files (in a crude way) or analyzing the bytecode (in a crude way).
Did I mention that I am doing a crude analysis?
There is no sophisticated parsing, no data flow analysis, nothing like that. Instead, I have knocked up a couple of simple scripts that mostly count things.
The areas covered are:
- Source code size. How much source code is in each project?
- Byte code size. How much bytecode is in each project, and how does that compare to the source code?
- Modularity. How many “units of modularity” are there, and how much code is in each module?
- Dependencies. How do the units of modularity depend on each other? A lot or a little? What does the dependency diagram look like?
- Cycles. How many circular dependencies are there? How many units of modularity are involved?
I’m not an expert, so I reserve the right to change the numbers if I get feedback from people who know what they are talking about!
The results were not as interesting as I hoped (unlike the previous analysis, which revealed big differences between F# and C# projects).
So, if you’re interested in reading a lot of boring numbers, read on, otherwise here is a summary:
- Source code size.
- Both projects are big, with almost half a million lines of code of C#, and 150K LOC of F#.
- As expected, over half the C# lines are “non-useful”: comments, braces, blank lines, etc. For F# the number is about a quarter.
- The source files are huge. Many are over a thousand lines, and some are over 5000 lines.
- Byte code size.
- The F# compiler project has more CIL instructions than Roslyn (core and C# combined), which surprised me.
- F# generates more CIL per source line than C# at a 4x ratio. Is this because F# is a more concise language or because the compiler is generating extra code to support functions? Perhaps a mix of both?
- Modularity.
- C# code has more units of modularity. There are over a thousand files in the Roslyn projects combined (and roughly the same as the number of classes), but less than a hundred files in the F# project (and 180 modules).
- An average F# file contains 26 type definitions, while an average C# file contains 1.7.
- The F# project contains a huge number of compiler generated types: 10,000.
- Dependencies.
- Both projects are similar, with the average class/module depending on 3-5 other classes/modules on average. For F# in particular, these numbers are much higher than other projects.
- A typical module in the F# compiler project has slightly fewer dependencies relative to a typical class in Roslyn.
- Both systems have a lot of classes/modules with a unusually high number of dependencies.
- Cycles.
- As with most F# projects, there are no cycles at all in the F# code.
- The C# code contains a number of large cycles – the largest has 899 mutually dependent classes.
So there you go. No amazing revelations. Sorry about that!
If you are really interested in the detailed numbers, here’s the process I used.
-
Roslyn. I got the Roslyn source from Codeplex and built it mostly without problems. Of the many projects in the repo, I decided to focus on only two: the core analysis assembly (Microsoft.CodeAnalysis.dll) and the C# analysis assembly (Microsoft.CodeAnalysis.CSharp.dll).
-
F# compiler. For the F# compiler, I got the source from github and again built without problems. The primary assembly is FSharp.Compiler.dll.
Note that there is another important assembly in the repo which contains the F# runtime library (FSharp.Core). but I have excluded it from this analysis because it is used with all F# programs, and is not part of the compiler.
-
My code. The code I used for this analysis is as follows (and is available on GitHub):
- For the source code analysis, I used this code, based on this snippet created by Kit Eason.
- For the byte code analysis, I used the Mono.Cecil library to extract types and dependencies. The code I used is here.
First off, let’s do a crude analysis of the source code. There is a little script, much beloved of F# advocates, that counts “useful” lines of code, excluding curly braces, null checks, and so on.
It’s not the most sophisticated analysis – there is no parsing involved, just simple regexes – but it does provide a basic overview of the differences between the two code bases.
Let’s see the results:
| Project | # of files | Lines of code | Blank lines | Comments | Braces | Nulls | Useful lines |
|---|---|---|---|---|---|---|---|
| Roslyn (core) | 555 | 115,010 | 15,507 | 19,093 (17%) | 28,243 | 2,190 | 49,977 (44%) |
| Roslyn (C#) | 738 | 342,178 | 44,046 | 39,171 (11%) | 92,402 | 10,202 | 156,357 (46%) |
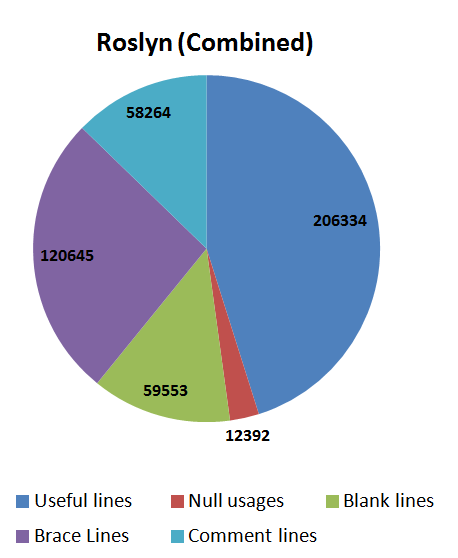
| Roslyn (core+C#) | 1,293 | 457,188 | 59,553 | 58,264 (13%) | 120,645 | 12,392 | 206,334 (45%) |
| F# Compiler | 96 | 162,435 | 17,589 | 25,975 (16%) | 109 | 31 | 118,731 (73%) |
The columns are self explanatory, I hope:
- Comments are lines containing only whitespace and comments.
- Braces are lines containing only whitespace and “{” or “}”.
- Nulls are lines containing “=” followed by “null”. That is, explicit equality checks or assignments.
- “Useful lines” are all the lines that are not blank, comments, nulls, or braces. As I said, this is a very crude metric.
Here is a pie chart showing the results for the two Roslyn projects combined.
And here are the results for the F# compiler.
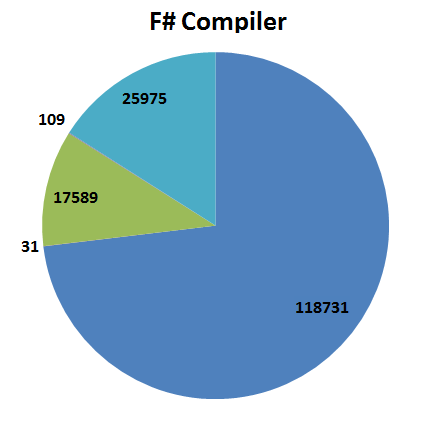
I should note that these metrics are not unusual – other analyses of C# vs F# code using the same approach have similar results.
For example, see this post by Simon Cousins and a study I did for my consulting site.
Another crude analysis we can do is to look at the LOC per file. Yes, I know that LOC is a bad metric, but in this case the results are quite interesting.
Analyzing the LOC per source file for both projects, I can see many files that are very large – 1000 lines in a file is very common, and many have over 5000 lines!
| Lines per file | Roslyn(Core) | Roslyn(C#) | Roslyn(both) | F# compiler |
|---|---|---|---|---|
| 0-200 | 408 files | 440 files | 848 files | 19 files |
| 201-300 | 48 | 77 | 125 | 12 |
| 301-500 | 43 | 87 | 130 | 9 |
| 501-800 | 29 | 58 | 87 | 10 |
| 801-1300 | 21 | 42 | 63 | 12 |
| 1301-2100 | 2 | 16 | 18 | 9 |
| 2101-3400 | 3 | 11 | 14 | 11 |
| 3401-5500 | 0 | 2 | 2 | 10 |
| >5500 | 1 | 5 | 6 | 4 |
| Total # of files | 555 | 738 | 1,293 | 96 |
| Total # of lines | 115,010 | 342,178 | 457,188 | 162,435 |
| Avg LOC per file | 207 | 464 | 354 | 1,692 |
Now it is commonly agreed that when you get to more than 500-1000 lines per file, it’s probably time to refactor. So if these were normal projects, I would be complaining that the number of large files was excessive.
But these are not normal projects. Compilers will always tend to have more code per file than normal, due to large lookup tables, huge switch statements, etc., so I wouldn’t presume to judge these numbers as bad.
The relevance of these numbers will become clear when it comes to analyzing the amount of code per module, next.
For this section, I will just compare the lines of code to the instructions generated. Again, not a great metric, but I think it is a reasonable way to get some idea of the output of the two compilers.
| Project | Code size | Total lines of code | Bytecode/ Total ;LOC | Useful lines | Bytecode/ Useful ;LOC | |
|---|---|---|---|---|---|---|
| Roslyn (core) | 426,558 | 115,010 | 3.7 | 49,977 | 8.5 | |
| Roslyn (C#) | 1,670,274 | 342,178 | 4.9 | 156,357 | 10.7 | |
| Roslyn (core+C#) | 2,096,832 | 457,188 | 4.6 | 206,334 | 10.2 | |
| F# Compiler | 2,765,997 | 162,435 | 17.0 | 118,731 | 23.3 | |
The columns are:
- Code size is the number of CIL instructions from all methods, as reported by the Mono.Cecil library. I think that this is a more accurate measure of code size than just counting the sizes of the binaries, because this approach will ignore resources and other non-code bits.
- Total lines of code is the total lines of source code, from the table above.
- Bytecode/Total LOC is the average number of CIL instructions generated from each source line.
- Useful lines of code is the “useful” lines of source code, from the table above.
- Bytecode/Useful LOC is the average number of CIL instructions generated from each “useful” source line.
-
Both projects are big. First off, let’s note that both of these are big projects. In comparison, the code for Entity Framework is around 270,000 instructions, almost ten times smaller than the F# compiler. The fact that they are so big means that no matter how good your refactoring or code reuse, there will be unavoidable complexity. We’ll see this later in the dependency diagrams.
-
The F# compiler project is bigger. It is also interesting (to me anyway) that the code size for these two Roslyn projects combined is quite a bit smaller than the F# compiler. I didn’t realize how big the F# compiler was!
-
F# generates more CIL per source line. If we look at the ratio of lines of code to CIL instructions generated, we can see that the F# code generates more CIL per line than the C# code. Including all lines (including blanks and braces) an average line of C# code generates 4.6 instructions, while an average F# line generates 17, almost 4x as many.
One way to look at this is that F# is more concise than C#, and that you get more bang for the buck with each line. Alternatively, you could make an argument that more CIL instructions doesn’t mean more functionality, and F# generating more instructions per line is bad, not good! Without a detailed comparison of similar code, it’s hard to know what’s happening behind the scenes, so I won’t speculate about what contributes to this difference.
In my earlier analysis, I was interested in measuring the “modularity” of projects, meaning how many modules there were, and how many dependencies there were between them.
The question then arises: what is the “unit of modularity”?
For both C# and F# I chose source files as the unit of modularity, because that is what we work with as developers. If everything is in one file, that’s a sign of high cohesion, but if you have to open 20 different files to understand some code, that’s a sign of low cohesion and high complexity.
For doing the dependency analysis, rather than using a source analysis tool, I’m using the compiled assemblies, treating top level classes (C#) and modules (F#) as proxies for files. Not perfect, but it is a good rule of thumb that there is one C# class or F# module per file. (For more on my reasoning, see the original post.)
Now that Roslyn is available, it would be interesting to do a true source based dependency analysis, and see if the results differed significantly.
Here are the modularity-related results for the projects:
| Project | Code size | Files | Top-level types | Authored Types | All types | Code/File | Top-level types/File | Authored types/File | Code/Authored type |
|---|---|---|---|---|---|---|---|---|---|
| Roslyn (core) | 426,558 | 555 | 611 | 891 | 990 | 769 | 1.1 | 1.6 | 479 |
| Roslyn (C#) | 1,670,274 | 738 | 1,086 | 1,310 | 1,462 | 2,263 | 1.5 | 1.8 | 1,275 |
| Roslyn (combined) | 2,096,832 | 1,293 | 1,697 | 2,201 | 2,452 | 1,622 | 1.3 | 1.7 | 953 |
| F# compiler | 2,765,997 | 96 | 180 | 2502 | 12,525 | 28,812 | 1.9 | 26.1 | 1,106 |
The columns are:
- Code size is the number of CIL instructions from all methods, as reported by Cecil.
- Files is the number of source files.
- Top-level types is the total number of top-level types in the assembly, using the definition above.
- Authored types is the total number of types in the assembly, including nested types, enums, and so on, but excluding compiler generated types.
- All types is the total number of types in the assembly, including compiler generated types.
I have extended these core metrics with some extra calculated columns:
- Code/File is the average number of CIL instructions generated per source file. This is a measure of how much code is associated with each unit of modularity. Generally, more is better, because you don’t want to have to deal with multiple files if you don’t have to. On the other hand, there is a trade off. Too many lines of code in a file makes reading the code impossible. In both C# and F#, good practice is not to have more than 500-1000 lines of code per file, but as I noted above, there are many exceptions to this guideline in these two projects.
- Top-level types/File is the average number of top level types (classes or modules) per file.
- Authored types/File is the average number of authored types per file. For C#, this would be nested classes, enums, etc. For F# these would be type definitions within a module.
- Code/Auth is the number of CIL instructions per authored type. This is a measure of how “big” each authored type is.
What can we deduce from these numbers?
- C# code has more units of modularity. There are over a thousand files in the Roslyn projects combined (roughly the same as the number of classes), but less than a hundred files in the F# project (or if counting modules instead, 180).
- C# types and F# types are similar size. Counting the directly authored classes and types, though, there are about as many in Roslyn as in F#. The “Code/Auth” numbers show that each authored type in F# generates roughly the same amount of CIL instructions as a C# class.
- F# files contain more types. The “Authored types/File” numbers show that for C# code, there is between one and two authored types per file, while for F#, that number is 26. That is, an average F# module contains 26 type definitions.
- The F# project contains a lot of compiler generated types. The F# compiler generates another 10,000 types in addition to the explicitly authored types! These are probably internal types to represent closures and cases in discriminated unions.
- There is a good correspondence between source files and top level types. Good practice says that you should have one class or module per file, and the “Top-level types/File” numbers bear this out, with F# being on the high end.
- The F# files are way big. The “Code/File” numbers shows that an average F# file generates a ginormous number of instructions. Partly this is due to the conciseness of F#, but mostly I think this is due to to the huge size of the files!
So far, we have looked at various “size” metrics. Now let’s look at dependencies between the modules.
Here are the results:
| Project | Top Level Types | Total Dep. Count | Dep/Top | One or more dep. | Three or more dep. | Five or more dep. | Ten or more dep. | Diagram | |
|---|---|---|---|---|---|---|---|---|---|
| Roslyn (core) | 611 | 1,757 | 2.9 | 52% | 29% | 15% | 7% | svg dotfile | |
| Roslyn (C#) | 1,086 | 10,649 | 9.8 | 93% | 77% | 62% | 19% | svg dotfile | |
| F# compiler | 180 | 779 | 4.3 | 64% | 37% | 29% | 18% | svg dotfile | |
{kind=link}
The columns are:
- Top-level types is the total number of top-level types in the assembly, as before.
- Total dep. count is the total number of dependencies between top level types.
- Dep/Top is the number of dependencies per top level type / module only. This is a measure of how many dependencies the average top level type/module has.
- One or more dep is the number of top level types that have dependencies on one or more other top level types.
- Three or more dep. Similar to above, but with dependencies on three or more other top level types.
- Five or more dep. Similar to above.
- Ten or more dep. Similar to above. Top level types with this many dependencies will be harder to understand and maintain. So this is measure of how complex the project is.
The diagram column contains a link to a SVG file, generated from the dependencies, and also the DOT file that was used to generate the SVG. See below for a discussion of these diagrams.
As you can see, the core Roslyn project and the F# project are not that different.
- The Roslyn core classes depend on just under 3 other classes, on average. This is consistent with the C# projects in the previous analysis (3.4 classes on average).
- The Roslyn C# classes depend on a whopping 10 other classes, on average. This is much higher than expected. I’m not sure why this might be, but it might be related to the special nature of a syntax tree.
- The F# compiler modules depend on just over 4 other modules, on average. This is much higher than the previous analysis of other F# projects (1.4 modules on average). I’m not sure why this might be either.
The average number of dependencies per top level type is interesting, but it doesn’t help us understand the variability. Are there many modules with lots of dependencies? Or does each one just have a few?
This might make a difference in maintainability, perhaps. I would assume that a module with only one or two dependencies would be easier to understand in the context of the application that one with tens of dependencies.
Rather than doing a sophisticated statistical analysis, I thought I would keep it simple and just count how many top level types had one or more dependencies, three or more dependencies, and so on.
Here are the same results, displayed visually:
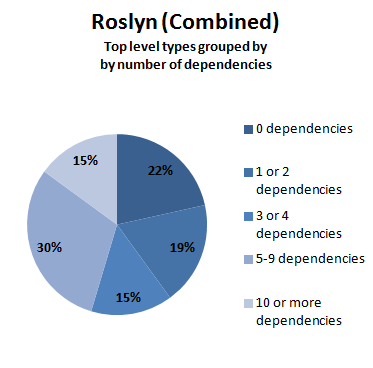
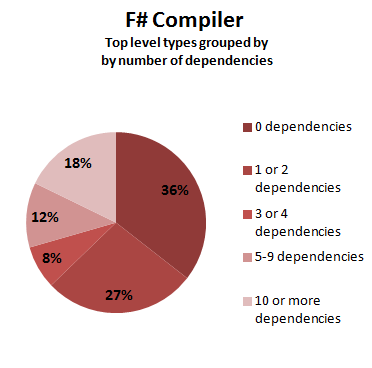
A quick analysis of these numbers shows that:
- A typical module in the F# compiler project has slightly fewer dependencies relative to a typical class in Roslyn.
- Both systems have a lot of modules with a high number of dependencies.
- If we compare these numbers with the projects in the previous analysis, the number of modules with many dependencies is much higher, for C# and especially for F#. (In the previous analysis, only 2% of F# modules had 10 or more dependencies)
It might be useful to look at the dependency diagrams now. These are SVG files, so you should be able to view them in your browser.
Here’s a sample of the one for Roslyn:

As you can see, there a lot of tangled lines in the dependency diagram!
Click to see the full SVG file. Note that it is very big – you will need to zoom out quite a bit in order to see anything!
And here’s a sample of the one for the F# compiler, which is just as bad:

Each diagram lists all the top-level types found in the project. If there is a dependency from one type to another, it is shown by an arrow. The dependencies point from left to right where possible, so any arrows going from right to left implies that there is a cyclic dependency.
The layout is done automatically by graphviz, but in general, the types are organized into columns or “ranks”. For example, the Roslyn diagram has about 40 ranks, and the F# compiler diagram has about 24.
How tangled the diagram looks is a sort of visual measure of the code complexity. For instance, if I was tasked to maintain the Roslyn project, I wouldn’t really feel comfortable until I had understood all the relationships between the classes, which implies in turn that I could follow all the lines in the diagram.
Both diagrams are pretty gnarly! There is a lot of complicated code there.
Finally, it’s not obvious from the high level overview, but in the F# diagram, all the arrows are going from left to right, while in the Roslyn diagram, the arrows are going both ways. We’ll see the difference this makes when we talk about cycles later.
In the previous analysis I did, the dependency diagrams for the F# code were a lot simpler than the C# ones, and I presented some reasons why this might be.
But in this case, for both systems, the dependency diagrams are really complicated. I don’t think we can draw any simple conclusions just by looking at them.
Finally, I’d like to examine the use of cyclic dependencies in both codebases.
I personally think that cyclic (or circular) dependencies are a major cause of complexity and should be eliminated or at least reduced to minimal levels. (If you want to know why I think they are bad, read this post).
Here are the cyclic dependency results for the three projects.
| Project | Top-level types | Cycle count | Partic. | Partic.% | Max comp. size | Diagram |
|---|---|---|---|---|---|---|
| Roslyn (core) | 611 | 6 | 94 | 15% | 71 | svg dotfile |
| Roslyn (C#) | 1,086 | 2 | 901 | 83% | 899 | svg dotfile |
| F# compiler | 180 | 0 | 0 | 0% | 0 | svg dotfile |
{kind=link}
{kind=link}
The columns are:
- Top-level types is the total number of top-level types in the assembly, as before.
- Cycle count is the number of cycles altogether. Ideally it would be zero. But larger is not necessarily worse. Better to have 10 small cycles than one giant one, I think.
- Partic. The number of top level types that participate in any cycle.
- Partic%. The number of top level types that participate in any cycle, as a percent of all types.
- Max comp. size is the number of top level types in the largest cyclic component. This is a measure of how complex the cycle is. If there are only two mutually dependent types, then the cycle is a lot less complex than, say, 71 or 899 mutually dependent types.
- The diagram column contains a link to a SVG file, generated from the dependencies in the cycles only, and also the DOT file that was used to generate the SVG. See below for an analysis.
As with most F# projects, there are no cycles at all in the F# code.
On the other hand, both of the Roslyn projects have a few large cycles that involve hundreds of types. The Roslyn C# analysis project has 83% of its classes participating in cycles!
Why such a large difference between C# and F#?
- In C#, there is nothing stopping you from creating cycles – a perfect example of accidental complexity. In fact, you have to make a special effort to avoid them.
- In F#, of course, it is the other way around. You can’t easily create cycles at all.
Here’s a small part of the cycle diagram for the Roslyn C# analysis project (click to see the full SVG file):

You can see that the CSharpSyntaxVisitor is at the centre of most of the dependencies. There are arrows in both directions between it and each syntax node.
True, many of them are generated from syntax.xml, but they are still dependencies.
If you zoom out a bit, you can see that the web of cyclic dependencies grows very large very quickly, showing a syntax tree with hundreds of classes.
In contrast, the F# code has no cycles at all. How does it manage this?
First, in F#, if you do have mutual dependencies, you can often refactor them away.
If that fails, you can just put all the related code in one module. It sounds obvious, but in an OO model it is hard to do without creating a God object.
In a functional design it is easier, because functions are not attached to a particular class and can be located wherever it is most convenient. It does mean that sometimes you get large files (like this one) but at least everything is one place.
Also in this particular domain (compilers), an OO model requires hundreds of little classes, one for each case, which naturally creates inter-class dependencies. And to traverse these classes you need to use the Visitor pattern, which in turn creates a lot of additional coupling between the Visitor and the classes it visits.
In F#, all these cases are typically combined into a single type (a discriminated union). The “visitor” pattern is then just a function that pattern matches on all the cases in the type (here’s a simple example), and you don’t need to create a special visitor class.
I hope this analysis has been interesting to you. I think that the influence of the implementation language is clearly apparent, but the effect is not as strong as in my previous analysis of C# and F# projects. Both projects are very large, and the complexity is very high, so it is hard to use something as crude as a dependency diagram to draw conclusions.
I don’t claim that this analysis is perfect, but I do think that it provides a useful starting point for further investigation and discussion. I’d be happy to get useful feedback, of course.